
Von Bäumen, Ästen und Blättern
Dieser poetische Titel leitet ein durchwegs prosaisches Thema ein: die Darstellung von Hierarchien in relationalen Datenbanken. Die Begrifflichkeiten Bäume, Wurzeln, Äste, Blätter stammen aus der Graphentheorie, die den theoretischen Hintergrund zu diesem Thema bildet.
Baumstrukturen begegnen einen in der Praxis immer wieder. Solange die Hierarchien fix sind, wie z.B. in den Relationen Jahr, Quartal, Monat usw., ist es einfach. Schwierig wird es bei den dynamischen Hierarchien, wie z.B. bei den Mitarbeiter/Vorgesetzten-Listen.
Mein persönliche Erfahrung mit dieser Struktur war eher unangenehm. Ich musste eine Datenbank abfragen, in der die Zusammensetzungen von Stoffgemischen als dynamische Hierarchie abgelegt waren. Die Abfragen dauerten sehr lange, oft mehr als 30 min, sofern sie dann nicht ergebnislos mit einer Fehlermeldung abbrachen. Das Hauptproblem lag in der Rekursivität der Abfragen, für die relationale Datenbanken prinzipiell nicht gut geeignet sind.
Dieser Algorithmus war definitiv ungeeignet. Doch was sind die Alternativen bzw. welche Optionen können überhaupt gewählt werden?
Optionen
Graphentheorie
Die Graphentheorie ist eine solide, wissenschaftliche Basis für hierarchische Algorithmen. Die mathematischen Sprache ist gewöhnungsbedürftig, aber dafür präzise. Ein gutes Beispiel findet sich in [ 1 ].
Wer vom theoretischen Zugang nicht so begeistert ist, der kann es mit den SQL-Gurus versuchen.
Joe Celko
Die Bibel zu diesem Thema stammt von Joe Celko [2]. In diesem Buch behandelt er auf 277 Seiten umfassend sämtliche Fragestellungen zu Hierarchien und Baumstrukturen. Funktionsweisen, Stärken und Schwächen der drei wichtigsten Methoden – Adjacency List, Path Enumeration und Nested Set Models – werden hier detailliert diskutiert.
Bill Karwin
Eine sehr prägnante Darstellung findet sich im Buch SQL Antipattern, Kapitel 3 „Naive Trees“ von Bill Karwin [4]. Auszug der tabellarischen Gegenüberstellung (S52):
| Design | Adjacency List | Path Enumeration | Nested Sets | Closure Table |
|---|---|---|---|---|
| Tables | 1 | 1 | 1 | 2 |
| Query Child | Easy | Easy | Hard | Easy |
| Query Tree | Hard | Easy | Easy | Easy |
| Insert | Easy | Easy | Hard | Easy |
| Delete | Easy | Easy | Hard | Easy |
| Ref. Integ. | Yes | No | No | Yes |
Vom selben Autor stammt auch die Präsentation Models for hierarchical data with SQL and PHP. Auch hier findet sich die tabellarische Gegenüberstellung (Folie 69). Allerdings mit einem Unterschied: „Path Enumeration“ in Rubrik „Query Child“ ist hier mit „Hard“ bewertet. Eine Begründung der anderen Einstufung ist nicht angegeben.
Vadim Tropashko
Ebenfalls sehr empfehlenswert ist das Buch von Vadim Tropashko: SQL Design Patterns [3]. Kapitel 5 behandelt „Trees in SQL“ und Kapitel 6 „ Graphs in SQL“, das mit einer ausgezeichneten Zusammenfassung abschließt. Einige Auszüge finden sich auch im Internet: Das Kapitel 6 und die erwähnte Zusammenfassung.
Performanz
Aussagen über die Performanz sind offenbar problematisch. Die wenigen systematischen Untersuchungen weisen eine sehr hohe Variabilität auf. Hardware, Servertyp, Optimierungsgrad, Datenstruktur, Datengröße u.v.a.m. beeinflussen die Ergebnisse wesentlich.
In [5] wird die Performanz von 5 Modellen in 8 Operationen gegenübergestellt (das Modell „Rekursion“ ist eine Adjazenzliste mit vom Server unterstützter Rekursion):
| Performanz | Adjazenz-Liste | Rekursion | Path-Enumeration | Nested-Sets | Closure-Table |
|---|---|---|---|---|---|
| Nachfolger finden (Teilbaum) | -- | + | ++ | ++ | ++ |
| Direkte Nachfolger finden | ++ | ++ | ++/+ | + | ++ |
| Vorgänger finden | -- | + | ++ | ++ | ++ |
| Direkten Vorgänger finden | ++ | ++ | ++/+ | + | ++ |
| Blatt einfügen | ++ | ++ | ++ | -- | ++ |
| Inneren Knoten einfügen | ++ | ++ | ++ | -- | ++/+ |
| Blatt löschen | ++ | ++ | ++ | - | ++ |
| Inneren Knoten löschen | --/- | + | ++ | --/- | ++/+ |
Legende: ++ sehr effizient; + effzient; - ineffizient; -- sehr ineffizient; [5]
Quantitatives zur Performance ist kaum zu finden. Eines der raren Beispiele stammt aus [6] und beruht auf folgende Randbedingungen:
- Intel Core i5; 2,4 Ghz; 4 GB RAM
- Win 10 Home Edition 64-bit
- Datenbank MS SQL 2014
- Anzeigenverwaltung mit 2902 Kategorien
- Mit 310 818 Anzeigen verteilt in den Kategorien
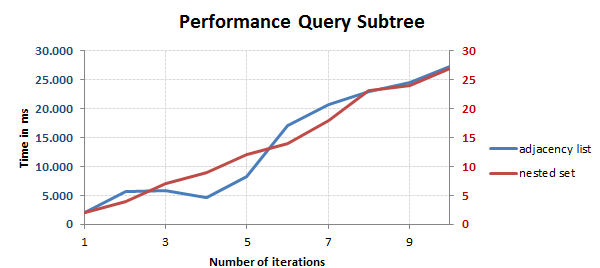
Daten aus [6], eigene Visualisierung
Im obigen Diagramm werden die Laufzeiten der Operation „Nachfolger finden (Teilbaum) bei einem Adjazenzlistenmodell und bei einem Nested-Set-Modell gegenübergestellt. Das Adjazenzlistenmodell ist demnach um rund das 1000-fache langsamer, als das Nested-Set-Modell. Dieses Ergebnis ist sicher nicht zu verallgemeinern, aber es gibt zumindest Anhaltspunkte und bestätigt darüber hinaus die quantitative Bewertung der obigen Tabelle aus [5]
Ein konkretes Beispiel
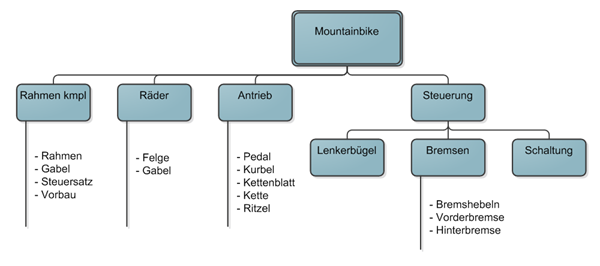
Adjanzenlisten Mountainbike
Ein anschauliches Beispiel ist die Stückliste für ein Mountainbike. Dabei wird das Produkt „Mountainbike“ strukturell aus Baugruppen, Unterbaugruppen und Einzelkomponenten zusammengesetzt.
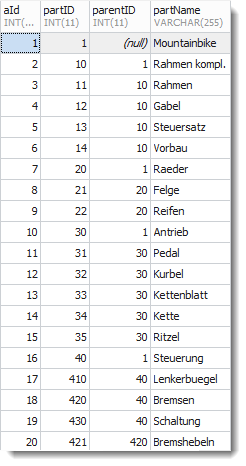
In der Adjanzenliste wird die Hierarchie durch die beiden Spalten partID und parentID dargestellt. Für die Wurzel ist die parentID = NULL . Die Tabelle wurde in MariaDB erstellt:
CREATE TABLE labdb.bikeparts (
aId INT(11) NOT NULL AUTO_INCREMENT,
partID INT(11) NOT NULL,
parentID INT(11) DEFAULT NULL,
partName VARCHAR(255) DEFAULT 'NULL',
PRIMARY KEY (aId),
UNIQUE INDEX partID (partID)
)
ENGINE = INNODB
Closure-Table Mountainbike
Adjanzenlisten sind schwierig abzufragen, weil die Hierarchie nur rekursiv aufgelöst werden kann. Die Closure-Table löst dieses Problem, indem sie der Abfrage alle Hierarchien bereits aufgelöst, zur Verfügung stellt. Die Struktur dieser Hilfstabelle ist so gewählt, dass die Abfragen möglichst einfach werden. Der Nachteil ist der stark erhöhte Speicherplatzbedarf.
Die Closure-Table kann auch manuell erstellt werden. Die Regeln sind einfach:- Jeder Datensatz besteht aus Vorfahr, Nachfahr und Distanz
- Alle Elemente selbstbezogen: Vorfahr=Nachfahr, Distanz=0
- Alle Verwandten 1. Grades: Vorfahr, Nachfahr, Distanz=1
- Alle Verwandten 2. Grades: Vorfahr, Nachfahr, Distanz=2
- Alle Verwandten n-ten Grades: Vorfahr, Nachfahr, Distanz=n
Schneller geht es jedoch mit einer gespeicherten Prozedur. Zuerst brauchen wir aber die Closure-Table:
CREATE TABLE labdb.bikeparts_closure (
ancestor INT(11) NOT NULL,
descendant INT(11) NOT NULL,
distance INT(11) DEFAULT NULL,
PRIMARY KEY (ancestor, descendant),
CONSTRAINT FK1a FOREIGN KEY (ancestor)
REFERENCES labdb.bikeparts(partID)
ON DELETE CASCADE ON UPDATE CASCADE,
CONSTRAINT FK1b FOREIGN KEY (descendant)
REFERENCES labdb.bikeparts(partID)
ON DELETE CASCADE ON UPDATE CASCADE
)
ENGINE = INNODB
Mit der graphischen Repräsentierung:
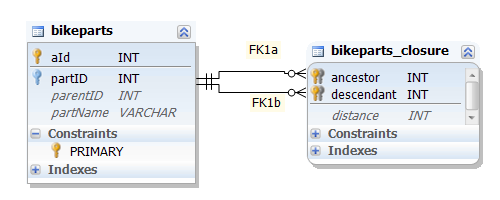
Die Closure-Table enthält für unser Beispiel 63 Vor-Nachfahr-Beziehungen. Das etwas mühsame, manuelle Erstellen kann durch eine Stored Procedure elegant umgangen werden. Die hier verwendete Prozedur beruht auf einer Idee, die in der Pentaho Mondrian Dokumentation publiziert wurde:
CREATE DEFINER = 'root'@'localhost'
PROCEDURE labdb.`populate_bikeparts_closure()`()
BEGIN
DECLARE distance int;
TRUNCATE TABLE bikeparts_closure;
SET distance = 0;
-- befülle closure mit selbsbezogenen Elementen (distance 0)
INSERT INTO bikeparts_closure (ancestor, descendant, distance)
SELECT partID, partID, distance
FROM bikeparts;
-- für jedes Paar (Ast, Blatt) in der Closure-Tabelle,
-- füge (Ast, Blatt->Nachfahr) von der Basistabelle hinzu
REPEAT
SET distance = distance + 1;
INSERT INTO bikeparts_closure (ancestor, descendant, distance)
SELECT bikeparts_closure.ancestor, bikeparts.partID, distance
FROM bikeparts_closure, bikeparts
WHERE bikeparts_closure.descendant = bikeparts.parentID
AND bikeparts_closure.distance = distance - 1;
UNTIL (ROW_COUNT()=0)
END REPEAT;
END
Und so sieht die befüllte und nach „distance“ sortierte Closure-Table aus:
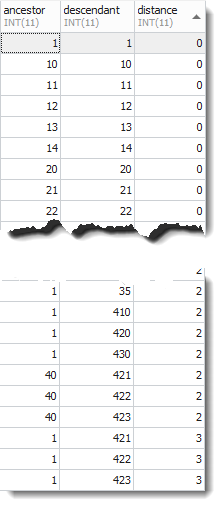
Zugegeben, die Datensätze der Closure-Table muten schon ein wenig seltsam an. Ob sich das wirklich lohnt, werden die Abfragen zeigen.
Abfragen
Abfrage: Alle Nachfahren
Ausgehend von vom Knotenpunkt „Steuerung“ (PartID=40) sollen alle Kinder aufgelistet werden. Dazu müssen nur alle Zeilen der Closure-Tabelle mit Vorfahr=40 abgerufen werden.
SELECT
bp.partID AS partID,
bp.partName AS partName
FROM (bikeparts bp
JOIN bikeparts_closure t
ON (bp.partID = t.descendant))
WHERE t.ancestor = 40
ORDER BY t.distance
Ergebnis:
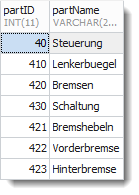
Das war leicht :-)
Abfrage: Alle Vorfahren
Um alle Vorfahren zu #422 „Vorderbremse“ abzurufen ist nur das Filter auf Nachfahr=422 zu setzen.
SELECT
bp.partID AS partID,
bp.partName AS partName
FROM (bikeparts bp
JOIN bikeparts_closure t
ON (bp.partID = t.ancestor))
WHERE t.descendant = 422
Ergebnis:
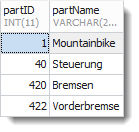
Auch das war leicht.
Abfrage: Meine Kinder
Diese Abfrage ist ident zur „Alle Nachfahren“ mit der zusätzlichen Einschränkung der direkten Verwandtschaft „distance=1“. Für dieses Beispiel ist der Ausgangspunkt Vorfahr = 1 (Mountainbike):
SELECT
bp.partID AS partID,
bp.partName AS partName
FROM (bikeparts bp
JOIN bikeparts_closure t
ON (bp.partID = t.descendant))
WHERE t.ancestor = 1
AND t.distance = 1
Ergebnis:

Auch das sehr einfach.
Abfrage: Alle Äste hübsch dargestellt
Die Idee zu dieser Abfrage hat Bill Karwin im Artikel Rendering Trees with Closure Tables publiziert. Sie beruht auf die MySQL Funktion GROUP_CONCAT, die eine String Aggregierung ( Zusammenhängen der Gruppenmitglieder) durchführt.
SELECT
GROUP_CONCAT(bp.partName ORDER BY bp.partID ASC SEPARATOR ' -> ')
AS path
FROM ((bikeparts_closure t2
JOIN bikeparts_closure t1
ON (t1.descendant = t2.descendant))
JOIN bikeparts bp
ON (bp.partID = t1.ancestor))
WHERE t2.ancestor = 1
AND t2.descendant <> t2.ancestor
GROUP BY t2.descendant
Ergebnis:
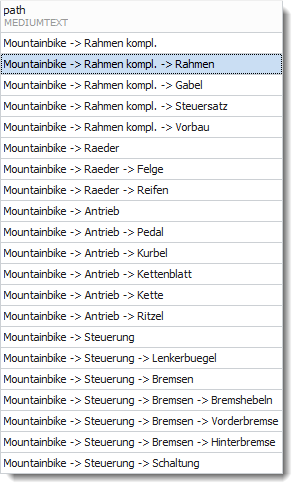
Der äußere Teil der Abfrage
SELECT
*
FROM bikeparts_closure t2
--
WHERE t2.ancestor = 1
AND t2.descendant <> t2.ancestor /* unterdrückt Wurzel */
GROUP BY t2.descendant
Liefert alle Nachfahren der Wurzel „ Mountainbike“, ausgenommen die Wurzel selbst. In unserem Beispiel sind das 21 Elemente.
Der innere Teil der Abfrage
JOIN bikeparts_closure t1
ON (t1.descendant = t2.descendant))
Ruft für jeden Nachfahren alle Vorfahren ab. Diese Liste der Vorfahren wird durch die CONCAT-Funktion aggregiert. Eine raffinierte und dennoch einfache Lösung.
Bonus
Visio kann die Adjanzenliste direkt aus der Datenbank darstellen. Am einfachsten geht es mit dem Assistenten:
Visio/Datei/Neu/Geschäft/Organigramm-Assistent/Erstellen ...
Die Daten können verknüpft oder kopiert werden. Ergebnis:
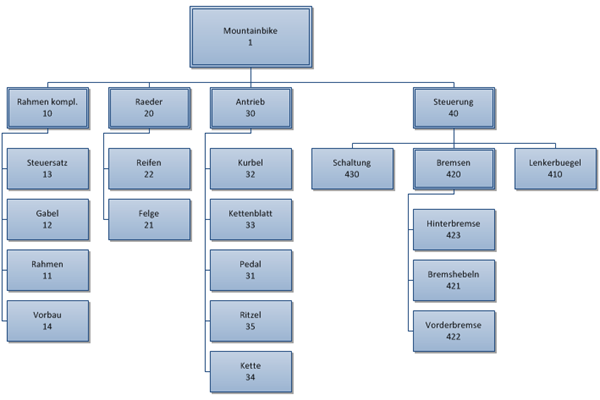
Einfach, schnell und beliebig tief. Das ist echt cool.
Referenzen
| [1] | Christoph Hermann: Effiziente Implementierung einer häufig abgerufenen hierarchischen Struktur in relationalen Datenbanksystemen, Technischer Bericht , Albert-Ludwigs-Universität Freiburg (2008) Link |
| [2] | Joe Celko’s: Trees and Hierarchies in SQL for Smarties, 2nd Edition, Morgan Kaufmann (2012) Link |
| [3] | Vadim Tropashko: SQL Design Patterns, Rampant Techpress (2006) Link |
| [4] | Bill Karwin: SQL Antipatterns, Avoiding the Pitfalls of Database Programming, The Pragmatic Bookshelf, Version 2010-6-9 (2010) Link |
| [5] | Frank Meyer: Aufbau einer Artenlistenverwaltung im Benthos-Projekt, Bachelorarbeit Uni Rostock (2015) Link |
| [6] | C.Györödi, R.Györödi: Improve Query Performance On Hierarchical Data. Adjacency List Model Vs. Nested Set Model, International Journal of Advanced Computer Science and Applications, Vol. 7, No. 4 (2016) Link |
| ∧ Seitenanfang |