
Prozessdatenmanagement in der Entwicklung
Auch die Entwicklung von Produkten oder Verfahren kann als Prozess gesehen werden. Warum also nicht, die Daten die dabei anfallen, als Prozessdaten bezeichnen? In diesem mehrteiligen Artikel steht das Zusammenführen heterogener Prozessdatenquellen und deren einfache Analyse im Vordergrund. Besonderer Wert wird auf Skalierbarkeit, Durchgängigkeit von R&D bis Fertigung, Nutzen und niedrige Kosten gelegt. Wobei in den Kosten nicht nur die Investitionskosten, sondern auch die Ausbildungskosten in das Know-how inkludiert sind.
Inhalt
Teil 4: Datenbereitstellung
Der Logik des bisherigen Titelgebung folgend, müsste Teil 4 „Datenbereitstellung mit MS“ heißen. Doch das wäre fehl am Platz, da die Datenbereitstellung keine Frage der Technologie, sondern eine Frage der Datenorganisation ist.
Die Strukturierung dieses Kapitels ist mir nicht leicht gefallen: bleibt man allgemein gültig, befindet man sich in einem wissenschaftlich, abstrakten Bereich von schwerer Verständlichkeit; arbeitet man mit Beispielen ist die Relevanz für den Leser unbestimmt. Ich habe mich für Beispiele entschieden, da mir die Verständlichkeit wichtiger ist.
Mein Ansatz ist: ein nachvollziehbares Beispiel wählen, einen von mehreren möglichen Losungswegen herauszugreifen, diesen skizzieren und auf den unsicheren Stellen einige Trittsteine platzieren. Ich vertraue darauf, dass in der Entwicklung die Daten selbst gut bekannt sind und es „nur“ darum geht, welche Ordnung man über die Daten legt.
Ziel der Ordnung
Der Anwender möchte seine Daten zum Sprechen bringen und zwar jederzeit, schnell und unkompliziert. So einfach ist es und so kaum erfüllbar. Eine realistische, technische Lösung, für die Ordnung der Daten, kann folgendes anbieten:
-
Das Datenmodell
- kann alle wichtigen Daten
- jederzeit,
- bereinigt,
- einfach
- und schnell,
- dem Anwender zur Verfügung stellen
- kann wachsen
- und kann elastisch auf Änderungen reagieren
Zu diesen Vorzügen gesellen sich auch einige Einschränkungen. Gehen wir diese durch:
- Das Datenmodell kann die Daten nicht zum Sprechen bringen, das muss schon der Anwender tun. Die technische Lösung kann nur die benötigten Daten bereitstellen.
- „Alle wichtigen Daten“ impliziert, dass nicht alle Daten verfügbar sind. Das ist der Preis für Einfachheit und Schnelligkeit. Diese Einschränkung wird gemildert durch „Elastizität“. D.h. sollten Daten nachträglich wichtig werden, so können sie auch nachträglich hinzugefügt werden.
- „einfach“ heißt: (i) die Ordnung der Daten ist konsistent und schnell erklärbar und (ii) jeder Anwender kann mit seinem bevorzugten Tool auf die Daten zugreifen. Eine eigenes GUI gibt es jedoch nicht.
Eine technische Lösung zu diesen Spezifikationen ist ein Data Warehouse, bestehend aus einem oder mehreren Data Marts. Damit ergibt folgendes strukturelle Gesamtbild von der primäreren Datenquelle bis zum Anwender:
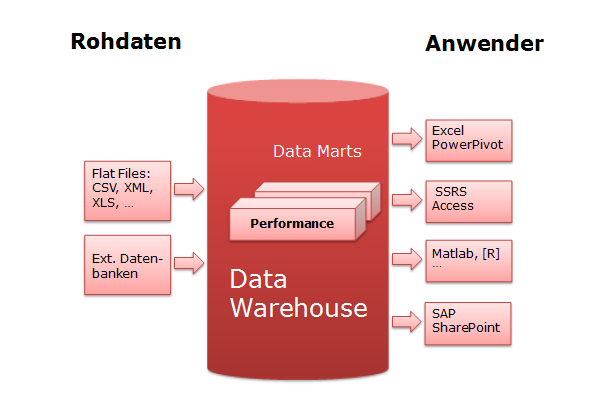
Systeme der Ordnung
Klar, am Data Warehouse führt kein Weg vorbei, doch wie aufbauen? Die "beste" Architektur wird bis heute in der Szene kontrovers diskutiert. Die Gurus sind Ralph Kimball und Bill Inmon. Ausgangspunkt waren die Bücher (erste Auflagen):
- W.H. Inmon: Building the Data Warehouse (1990)
- R. Kimball: The Data Warehouse Toolkit (1996)
In den aktuellen Auflagen sind sie auch heute noch DIE Referenz. Wer sich in die Materie vertiefen möchte, ist mit diesen Büchern gut beraten. Die Kernunterschiede:
| Ralph Kimball | Bill Inmon |
|---|---|
| Das DWH ist die Summe der Data Marts. Data Marts können gemeinsame Tabellen haben. | Das DWH besteht aus einem zentralen Datenlager und mehreren, davon abgeleiteten, Data Marts |
| Data Marts haben eine einfache, dimensionale Struktur | Das zentrale Datenlager hat meist komplexe relationale Verknüpfungen |
| Bottom-Up Design | Top-Down Design |
| Vergleichsweise einfach | Ziemlich komplex |
Richtig oder falsch ist hier nicht die Frage, sondern was kommt meinen Anforderungen am nächsten. Für das Prozessdatenmanagement in der Entwicklung ist es ganz klar Ralph Kimball. Wobei Mischformen ja nicht verboten sind. Wenn sie nützlich sind, warum nicht?
Struktur des Data Marts
Die einfachste Form eines Data Mart besteht aus einer (1) Faktentabelle und mehreren Dimensionstabellen in Sternstruktur. Die Faktentabelle enthält die Maßzahlen und die Dimensionstabellen den beschreibenden Kontext.
Faktentabelle
Maßzahlen sind Zahlen, die sich für eine Zusammenfassung eignen. Maßzahlen können auch binär sein, wie z.B. gut/schlecht. Zur Konsolidierung werden Mittelwert Streuung, Min, Max, Summe, Anzahl, Ausbeute etc. verwendet. Die Personal-ID ist zwar auch eine Zahl, aber keine Maßzahl, sondern eine Dimension.
Die Faktentabellen können sehr groß werden. Sie haben i.a. nur wenige Spalten, aber sehr viele Zeilen. Die Datentypen sollten daher gut überlegt werden. Char-Variablen wären hier äußerst ungünstig.
Auch die Granularität sollte gut überlegt werden. Ist es wirklich notwendig alle Einzelwerte aufzunehmen, oder reicht nicht auch eine Zusammenfassung? Wenn z.B. die Temperatur alle 1s aufgezeichnet wird, reicht dann nicht auch der 1min-Mittelwert zur Ablage im DWH? Wenn eine hohe Detaillierung und eine tiefe Historie gefordert werden, ist eine Aufteilung in 2 Data Marts möglicherweise sinnvoll: die Historie mit zusammengefassten Werten und eine aktuelle Periode mit den Einzelwerten.
In einem Abrechnungssystem für Probenanalysen wird man hingegen jede Einzelanalyse aufzeichnen wollen. Die Analysenwerte selbst sind für diesen Zweck aber unnötig. Die Granularität ist hier die Analysendurchführung. Innerhalb eines Data Mart sollte die Granularität konstant gehalten werden.
Dimensionstabellen
Die Dimensionen beschreiben die Maßzahl in textueller Form. Dimensionstabellen sind i.a. kleiner als Faktentabellen, haben weniger Zeilen und mehr Spalten. Die Dimensionstabellen sind hoch redundant, mit viel Text. Das ist einer der Gründe, für die gute Verständlichkeit. Einige Beispiele für Dimensionen und ihre Attribute:
| Dimension | Attribute |
|---|---|
| Datum | Jahr, Quartal, Monat …, Sommer Winter …, |
| Zeit | Stunde, Minute .. Tag, Nacht, Frühschicht, Normalschicht, Spätschicht … |
| Messgerät | S/N, Typ, Hersteller, Baujahr, Messbereich, Richtigkeit, Standort … |
| Material | Materialgruppe, Charge, Lieferdatum, Haltbarkeit … |
| Lieferant | Sparte, Name, Adresse … |
| Prozessschritt | Nr, Beschreibung, Prozess, Revision, HPV-Link |
| Prozessergebnis | Linie, Stückzahl-Ein, Stückzahl-Aus, Stückzahl-OK, Startzeit, Endezeit, Fehlergruppe, Fehlerdetail |
| Produkt | Sortiment, Produktfamilie, Produktgruppe, Produkt, Beschreibung |
| Test | Testgruppe, Testfall, Testschritt, Sollwert, OG, UG, Beschreibung … |
Jede Dimensionstabelle sollte nur eine Dimension darstellen. Die Attribute der Dimension sind in den Spalten abgelegt. Die Attribute sind häufig hierarchisch aufgebaut. Abschließend noch ein ausgearbeitetes Beispiel für eine Datum/Zeit-Dimensionstabelle:
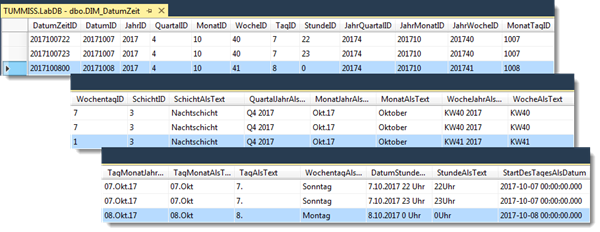
Der Primärschlüssel „DatumZeitID“ setzt sich aus JJJJMMTThh zusammen. Die gewählte Granularität beträgt 1h.
Sternschema
Die Dimensionstabellen gruppieren sich sternförmig um eine Faktentabelle. Jede Dimensionstabelle hat genau einen primären Schlüssel, der eine 1:N Verknüpfung mit der Faktentabelle herstellt. Die Primärschlüssel der Dimensionstabellen sind die Fremdschlüssel in der Faktentabelle. Die Faktentabelle benötigt an sich keinen eigenen Primärschlüssel, da die Kombination der Fremdschlüssel eindeutig sein sollte. Ein Surrogatschlüssel (künstlicher Schlüssel) ist aber dennoch empfehlenswert, weil es den ETL-Prozess erleichtert.
Die u.a. Abb. zeigt das logische Design eines Data Mart für einen Dauertest, bestehend aus 3 Dimensionstabellen und 1 Faktentabelle im Sternschema. Es sind nur die Basisattribute angeführt, in der Praxis werden viel mehr Attribute sinnvoll sein.
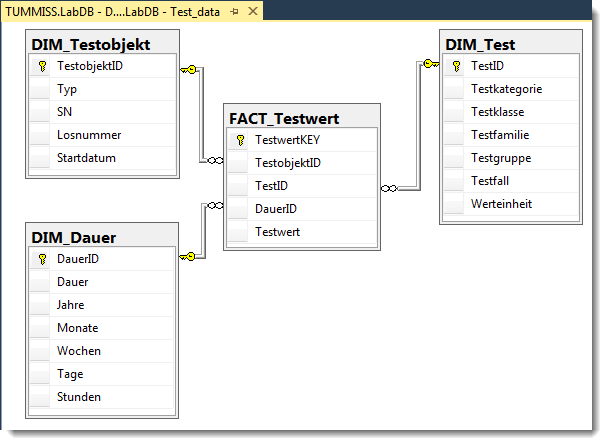
Die Dimension "Testobjekt" ist selbsterklärend. Die Dimension "Test" hat 4 Hierarchiestufen für die Testfälle, die alle verflacht sind. Das ist typisch für Dimensionstabellen. Beispiele für Werte:
- Testfall – die kleinste Einheit mit 1 Messwert: Sensitivität; Kontrollmittel A …
- Testgruppe: Kalibrierung; Qualitätskontrolle …
- Testfamilie: Startup; Lebensdauer …
- Testklasse: Freigabe; Monitoring …
- Testkategorie: Produktion; Entwicklung …
Die Dimension "Dauer" hat hier die Granularität von 1h und bezieht sich auf das Startdatum im DIM_Testobjekt. Die DauerID ist einfach die Dauer in Stunden. Zusätzlich ist die Dauer als zeitvariable („Dauer“) und aufgespalten in Jahre+Monate+ … dargestellt. Dies Aufspaltung ist wichtig für einfach durchzuführende Aggregationen und Vergleiche.
Die Faktentabelle "Testwert" hat die Granularität von 1h. D.h., dass alle Ereignisse vom gleichen Typ, die innerhalb von 1h auftreten, zu einem Mittelwert o.ä. zusammengefasst werden müssen, bevor sie in der Faktentabelle abgelegt werden können.
Laden des Data Marts
Bei einfachen Datenstrukturen kann das Data Mart direkt von den Rohdaten ausgehend, mit einem ETL-Tool, geladen werden. Bei komplexeren Datenstrukturen ist ein zweistufiger Prozess sinnvoll. Im ersten Schritt sammelt, verknüpft, bereinigt und transformiert ein ETL-Prozess die Daten in einem temporären Zwischenspeicher (Staging Area). Erst wenn dieser Schritt erfolgreich abgeschlossen wurde, wird in einem 2. Schritt die Daten in das DWH geladen.
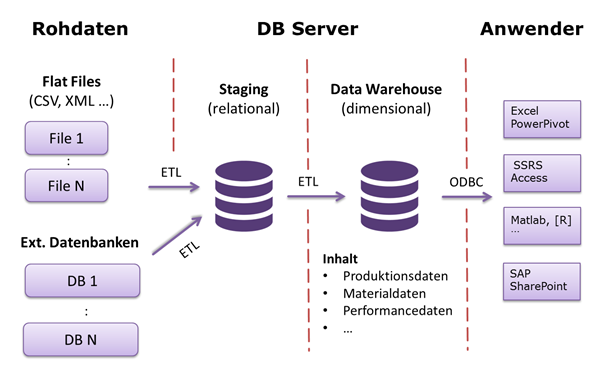
Resümee Datenbereitstellung
Die Datenorganisation über Data Marts ist eine ausgezeichnete Methode, um den Anwender einfach durchzuführende und sehr performante Analysen zu ermöglichen. Ein Data Mart aufzubauen ist nicht schwierig. Die Anwendung einiger weniger Grundregeln genügen, um ein funktionierendes Data Mart zu bekommen. Jeder IT-affiner Anwender kann sich dieses Grundwissen in kurzer Zeit aneignen. Das bestehende, sehr umfangreiche Know-How zu diesem Thema hat man natürlich so nicht zur Verfügung, aber vieles von dem fehlenden Wissen kann durch sehr gute Kenntnisse über die Daten kompensiert werden. In der Entwicklung setze ich das als gegeben voraus.
Ein zweiter Aspekt ist das Laden der Daten. Bei einfachen Datenstrukturen und reduzierten Anforderungen an die Verifizierung der Daten kann mit dem Assistenten gearbeitet werden, den man nach vergleichsweiser kurzer Einarbeitungszeit beherrscht (s. Teil 2 und Teil 3). Bei höheren Anforderungen an Bereinigung, Transformation und Automatisierung sind SSIS-Projekte das Mittel der Wahl. So ganz einfach ist das allerdings nicht mehr, mit einer Einarbeitungszeit von mindestens 1 Wo ist zu rechnen.
In der Entwicklung ist Vollautomatisierung nicht immer erstrebenswert. Bei manuellen Zwischenschritten ist auch der Einsatz anderer Tools zur Transformation der Daten möglich, z.B. Access oder auch Matlab. Diese Vielzahl an Möglichkeiten erlaubt es für jedes Umfeld einen schnell gangbaren Weg zu finden.
| < Teil 3 | ∧ Seitenanfang | Teil 5 > |