
Prozessdatenmanagement in der Entwicklung
Auch die Entwicklung von Produkten oder Verfahren kann als Prozess gesehen werden. Warum also nicht, die Daten die dabei anfallen, als Prozessdaten bezeichnen? In diesem mehrteiligen Artikel steht das Zusammenführen heterogener Prozessdatenquellen und deren einfache Analyse im Vordergrund. Besonderer Wert wird auf Skalierbarkeit, Durchgängigkeit von R&D bis Fertigung, Nutzen und niedrige Kosten gelegt. Wobei in den Kosten nicht nur die Investitionskosten, sondern auch die Ausbildungskosten in das Know-how inkludiert sind.
Inhalt
Teil 6: Alternative Open Source
Die Open Source (OS) Szene ist äußerst aktiv. Es gibt eine ganze Palette von Möglichkeiten, um ein Data Warehouse ausschließlich aus OS-Komponenten aufzubauen. Zur Auswahl stehen:
- Red Hat, CentOS, Fedora
- Debian, Ubuntu
- Mageia u.a. Linux Distributionen
- …
- Firebird
- MariaDB
- MongoDB
- MySQL Community (free)
- PostgreSQL
- …
- MySQL Workbench (free)
- HeidiSQL
- DBeaver
- dbForge Studio Express (free)
- phpMyAdmin
- …
- Kettle
- Talend Open Studio
- CloverETL Community (free)
Auswahl der OS-Komponenten
Betriebssystem
Die erste Frage ist die nach dem Betriebssystem. Open Source heißt Linux. Wirklich Linux? Hmm. In jedem Entwicklungslabor wird ein frei verfügbarerer Rechner ziemlich sicher ein Windows-Rechner und kein Linux-Rechner sein. Dieses Bild zeichnet auch die Feedback-Statistik von MariaDB:
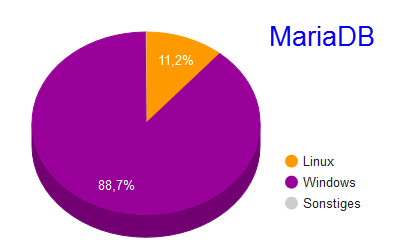
(Quelle: MariaDB , URL: http://mariadb.org/)
Ich werde für diese Demo Windows Server 2012 R2 verwenden, es sind aber alle Windows Editionen ab 7 geeignet. Für den Einstieg ist das Windows Betriebssystem ein realistisches Szenario. Bei hohen Leistungsanforderungen ist aber Linux überlegenswert, da derzeit das Clustering nur unter Linux unterstützt wird.
Datenbank Server
Einer der weltweit am häufigsten eingesetzten OS-Datenbank ist MySQL. Nativ läuft es mit Linux und PHP auf zahllosen Web-Servern. Eine echte Quantifizierung ist aber gar nicht so einfach, denn der bei kommerziellen Produkten so bewährte Indikator „Summe der Lizenzkosten“ funktioniert bei den OS-Produkten naturgemäß nicht.
Einen sehr interessanten Ansatz verfolgt das österr. Beratungsunternehmen solid IT auf ihrem Portal DB-Engines. Sie bestimmen die Popularität der Systeme durch Web-Analysen. Parameter sind: Anzahl der Suchergebnisse, Häufigkeit von Diskussionen, Job-Angebote, Anzahl von Bezug nehmenden Profilen in LinkedIn u.a.m.
Demnach sind die populärsten DB-Engines: Oracle, MySQL und MS-SQL Server. Die ersten drei der Rangliste liegen fast gleichauf, aber deutlich vor dem vierten PostgreSQL.
Aktuell ist MySQL kein OS-Projekt mehr, es wurde von Sun bzw. Oracle gekauft und wird als kommerzielles Projekt weitergeführt. Die Community Edition ist zwar free, aber eben nicht Open Source. Der Kauf initiierte die Abspaltung MariaDB. Die Namen „My“ und „Maria“ kommen von den Vornamen der Töchter des Hauptentwicklers Ulf M. Widenius (Wikipedia).
Meine Wahl fiel auf MariaDB, die universelle Einsatzbarkeit, die aktive Community, die Kompatibilität zu MySQL und der einfache Einstieg waren die primären Gründe.
ETL Tool
Die Entsprechung von SSIS im MS-Umfeld sind Kettle, Talend und CloverETL im OS-Umfeld. Das richtige Tool zu wählen hängt sehr vom Daten-Umfeld und der Einbettung in die BI-Landschaft ab. Für das Ziel dieser Artikelserie sind sie nicht unbedingt erforderlich, sodass wir eine Diskussion jetzt nicht führen müssen. Glücklicherweise, denn das Thema ist komplex und würde sicher den Rahmen gehörig sprengen.
Datenbank Management
Maria DB wird mit HeidiSQL zum Verwalten der Datenbank ausgeliefert. Von einem harmonischen Miteinander ist daher auszugehen. Die Bedienung von HeidiSQL ist einfach, der Funktionsumfang ist hoch. Dem Design der GUI sieht man ein bisschen die lange Historie an. Die Unterstützung von Flat File Importen ist leider nur rudimentär.
Eine Alternative ist die OS-SW DBeaver. Der Leistungsumfang ist sehr hoch und das GUI-Design ist sehr gelungen. Der hohe Funktionsumfang macht die Anwendung etwas schwieriger. Leider auch hier: keine Unterstützung beim Import von fixed-width und XML-Files.
MySQL Workbench scheint laut Spezifikationen ähnliche Vor- und Nachteile wie DBeaver zu haben, habe diese SW aber nicht erprobt.
Eine weitere Alternative ist dbForge Studio for MySQL. Eine großer Funktionsumfang, einfache Bedienung und eine sehr gelungene GUI zeichnet diese SW aus. Ein Alleinstellungsmerkmal ist die sehr gute Unterstützung beim Import von allen Flat-File Typen! Leider kein Open-Source-Produkt. Der Preis der Pro Edition ist jedoch mit 250$ sehr moderat. Die Express-Edition ist sogar kostenlos, hat aber Einschränkungen: Es können z.B. nur 50 Zeilen von einem XML-File importiert werden.
Für diese Demo werde ich überwiegend dbForge Studio Express verwenden und nur fallweise auf HeidiSQL und DBeaver zurückgreifen.
Setup Open-Source Umfeld
MariaDB installieren
(1) Download aktuelle Version von mariadb.org: Wähle das MSI-Paket für Windows x86_64
(2) Starte mariadb-10.2.10-winx64.msi
(3) Akzeptiere die Lizenzvereinbarung
(4) Datenverzeichnis wählen (es ist nicht das Programmverzeichnis!). Es ist empfehlenswert NICHT das vorgeschlagene MS-Programmverzeichnis zu wählen, sondern ein eigenes Verzeichnis außerhalb zu erstellen. Damit vermeidet man manches Rechteproblem. Alle anderen Einstellungen passen:
(5) Passwort und Rechte für den Benutzer „root“ vergeben:
(6) Default DB Einstellungen belassen:
(Der Wert für "Buffer pool size" wird automatisch bestimmt und hängt von der Größe des verfügbaren RAM ab)
(7) Feedback deaktiviert lassen:
(8) Next – Install – Done
Das Installationsprogramm erzeugt neue Einträge im Startmenü:
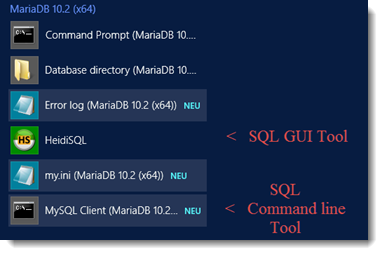
- „Command Prompt“ ist das Windows Command Line Tool mit einer PATH-Variablen die auf die MariaDB Binaries zeigt. Damit können MariaDB-Befehle ausgeführt werden.
- „Database Directory“ öffnet das MariaDB/data-Verzeichnis im Explorer
- „Error log“ öffnen im Notepad
- „HeidiSQL“ Graphisches Tool zum Verwalten der Datenbanken und Ausführen von SQL-Befehlen. Entspricht etwa dem SSMS von MS
- „my.ini“ öffnet den Konfigurationsfile im Notepad
- „MySQL Client“ ein Command Line Tool mit dem SQL-Befehle ausgeführt werden können
Datenbank erstellen
Wir starten die Client-SW dbForge Studio auf demselben Rechner, auf dem die Server-SW MySQL läuft. In dieser Konfiguration heißt der Server „localhost“ und hat die IP 127.0.0.1
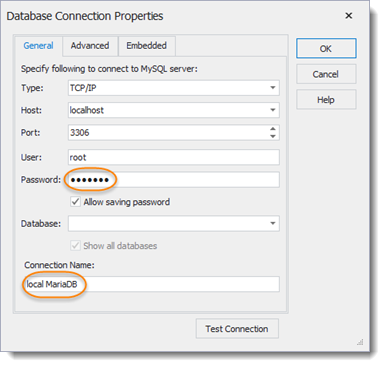
(9) Beim Erststart von dbForge Studio öffnet der Verbindungsmanager das Einstellungsfenster. Als Passwort ist das bei der Installation definierte einzugeben. Das Feld „Database“ lassen wir vorerst leer:
(10) Die Default-Datenbanken am Server werden angezeigt: 3 System-DB und eine leere Test-DB:
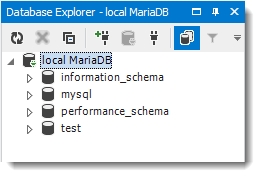
(11) Datenbank „LabDB“ anlegen:
Rechtsklick auf Server „local MariaDB“ – New Database :
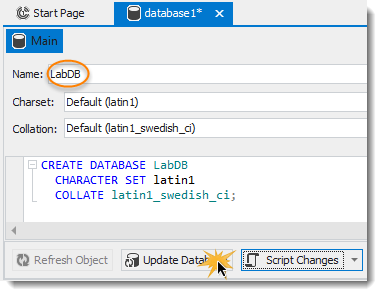
Mit Collation ist die Art der Zeichensortierung zu verstehen. Hier swedish_case_insensitive. Der Defaultwert ist so, weil der Entwickler von MySQL Schwede war.
UT71 Temperatur-File importieren
Dieser Fixed-Width File wurde vom Messgerät UT71D generiert. Jede Datenzeile enthält genau einen Messwert und einen Konfigurationswert. Das Format ist in Teil 2 detailliert beschrieben.
(12)Fixed-With File „UT71Dcapture.txt“ importieren
Wir können die Ziel-Tabelle vorher anlegen oder
sie vom Importassistenten anlegen lassen und sie anschließend editieren. Das letztere ist der bequemere Weg.
Rechtsklick auf Tables ... Import Data:
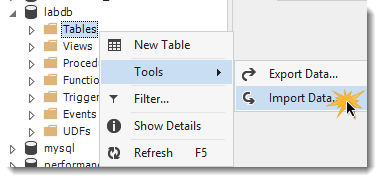
(13) Format und Quelle angeben:
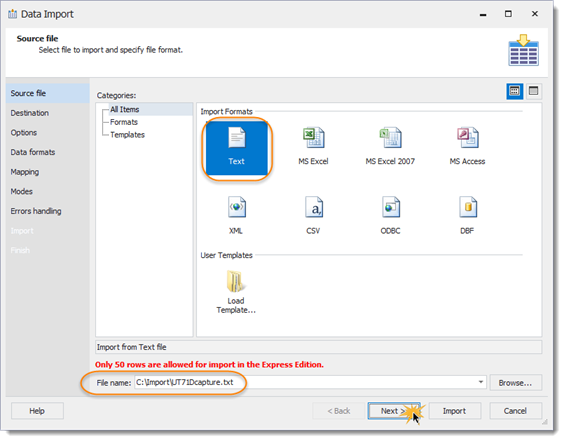
(14) Ziel angeben. Default-Werte belassen:
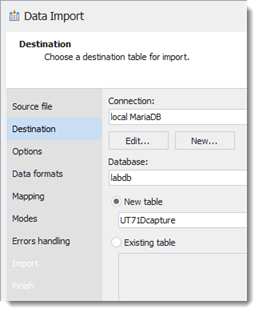
(15) Spaltenbreiten angeben
Splitting auf „Manual“ setzen und Doppelklick ins Lineal um eine zusätzliche Trennlinie zu erzeugen. Mit der
Maus lässt sie sich auch nachträglich verschieben. Löschen, indem man Splitting kurz auf Delimiter setzt:
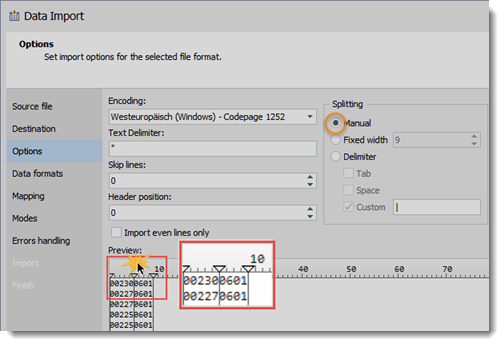
(16) Text-File importieren
Alle anderen Einstellungen können default bleiben. Klick auf Import und
fertig:
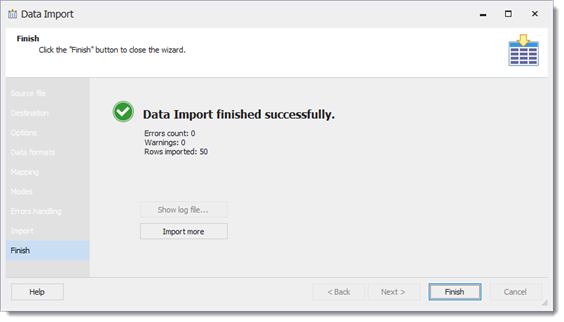
Die Express-Edition importiert nur 50 Zeilen und unser Import-Template kann auch nicht gespeichert werden :-(
(17) Tabelle editieren
Sinnvolle Namen geben und primären Schlüssel hinzufügen:
Vorher:
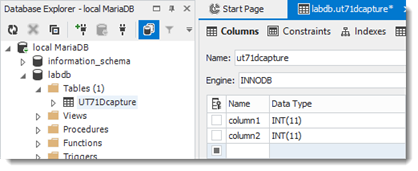
Nachher:
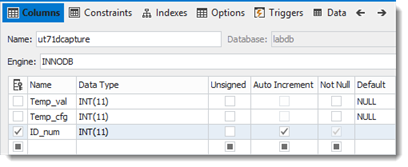
... und „Update Database“.
(18) Tabelle anzeigen
Reiter „Data“:
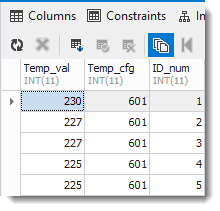
(19) Fertig!
Transformation der Daten
Diese Aufgaben übernehmen normalerweise die ETL-Tools, als Teil des Extract-Transform-Load Prozesses. Wir haben diese Tools nur gestreift, da sie komplex sind und ihre Stärken erst bei einem hohen Automatisierungsgrad ausspielen. Im Moment ist das nicht unser Fokus.
Auch in unserem Beispiel wäre eine Transformation sinnvoll: die Umrechnung des kommalosen Temperaturwertes in einen °C-Wert. Leider unterstützt keiner der bisher verwendeten Importassistenten eine Transformation von Daten. Es gibt jedoch einen Trick, eine Berechnung während des Importes von Daten in einer Tabelle vorzunehmen: die virtuelle, persistente Spalte, in der auch ein Ausdruck verwendet werden kann. Wir werden die berechnete Spalte jetzt nützen um aus dem Temperaturwert einen °C-Wert zu berechnen.
(20) Berechnung der °C hinzufügen
Dabei wird der Tabelle eine berechnete Spalte hinzugefügt:
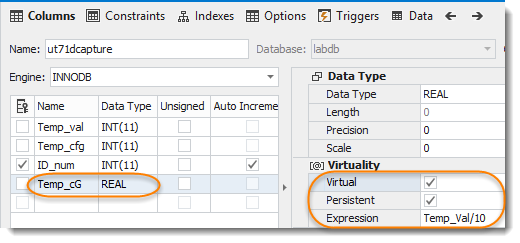
(21) Nach „Update Database“ ist die Tabelle um die Temperatur in °C erweitert:
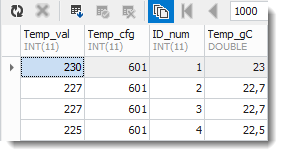
(22) dbForge Fehler in der DDL-Sicht der Tabelle
DDL steht für Data Definition Language. dbForge erkennt die Virtualität nicht mehr:
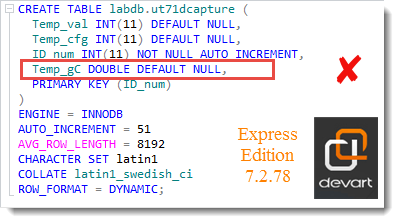
Aber DBeaver erkennt sie:
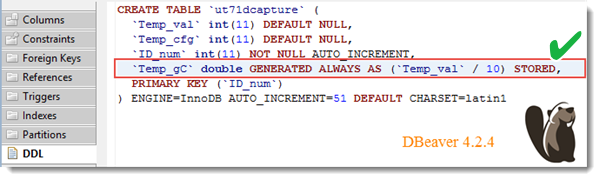
Auch HeidiSQL erkennt sie:
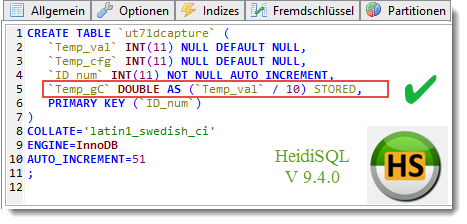
Möglicherweise liegt es daran, dass dbForge explizit nur MariaDB bis V10.0 unterstützt, aktuell aber V10.2 läuft. Es ist manches mal ganz gut, eine zweites, unabhängiges System zu haben …
BGA XML-File importieren
Der XML-Import in dbForge Studio ist ident zum SSMS Add-In Data Pump. Anwendung siehe Data Pump in Teil 3
Zusammenfassung Alternative Open Source
Die kommerziellen, Closed-Source Hersteller von Datenbanken – IBM, Microsoft, Oracle und SAP – dominierten Jahrzehnte den Markt. Diese Bild ändert sich zur Zeit rasant: die Open-Source DB-Engines gewinnen zunehmend Anteile.
Zu den größten Vorzügen der OS-Produkten zählen – neben dem free – die erstaunlich breite Unterstützung unterschiedlichster Systeme. Gleichzeitig ist das auch die Achillesferse, da Änderungen über Systeme hinweg, kaum zu organisieren sind.
Der Gegenpol ist Microsoft: die Integration der MS-Komponenten ist hervorragend und die Updates sind sehr gut aufeinander abgestimmt, aber der Zugriff auf Komponenten außerhalb der MS-Welt ist oft eine Qual.
Open Source oder Microsoft?
Unser Anforderungsprofil entscheidet diese Frage nicht, mit beiden Systemen sind die in Teil 1 formulierten Ziele zu erreichen. Es ist weniger eine Frage der Gewichtung spezifischer Vor- bzw. Nachteile als vielmehr eine Frage der grundsätzlichen Haltung, die von den Stakeholdern vertreten wird. Eine Diskussion wird das rasch sichtbar machen.
| < Teil 5 | ∧ Seitenanfang | Teil 7 > |